Endogeneity and Bias: Correlations II
- Here is where checking correlations between variables helps:
# Make a correlation plotlibrary(corrplot)corrplot(corr, type="upper", method = "number", # number for showing correlation coefficient order="original")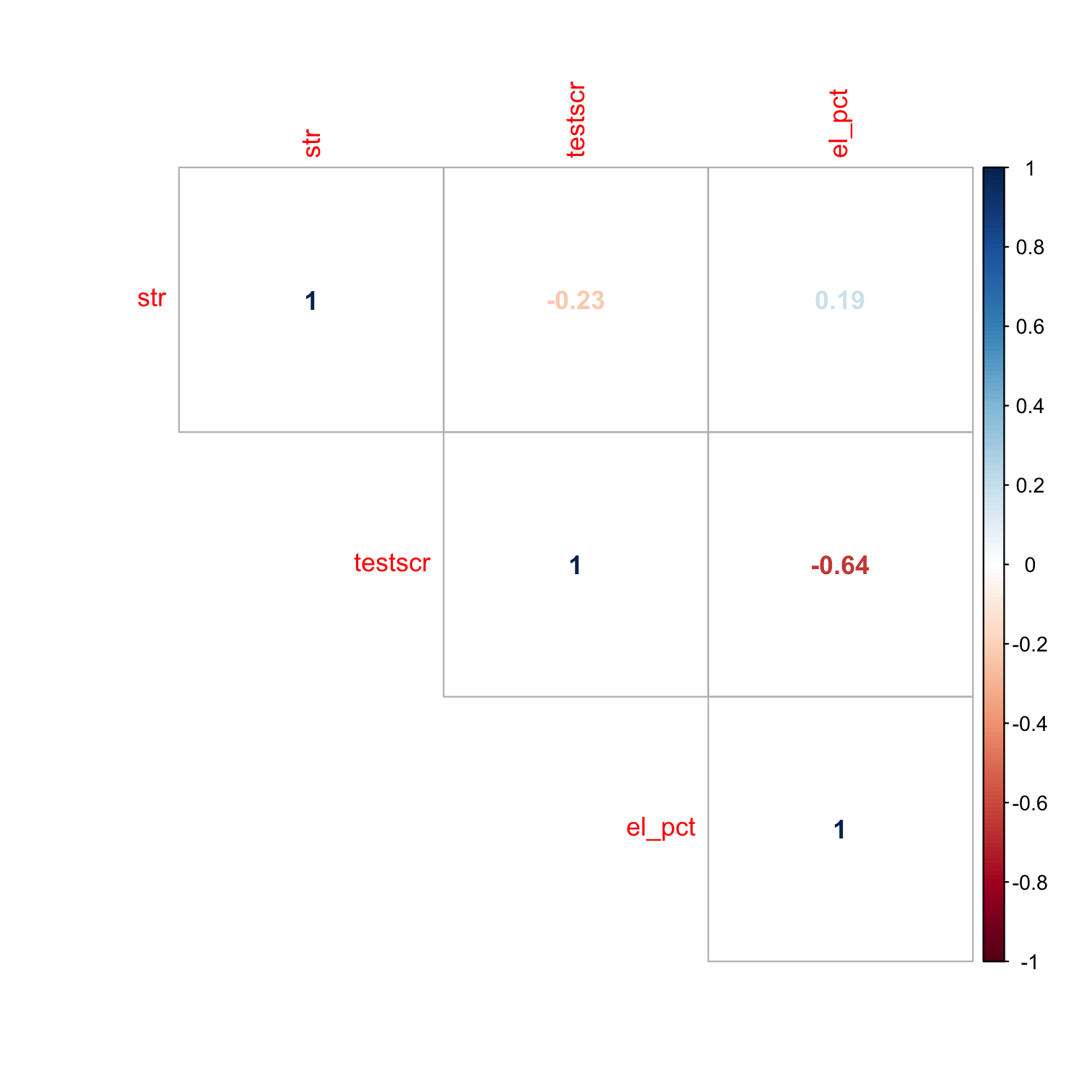
el_pctis strongly correlated withtestscr(Condition 1)el_pctis reasonably correlated withstr(Condition 2)
Look at Conditional Distributions II
ggplot(data = CASchool)+ aes(x = testscr, fill = ESL)+ geom_density(alpha=0.5)+ labs(x = "Test Score", y = "Density")+ theme_classic(base_family = "Fira Sans Condensed", base_size=20)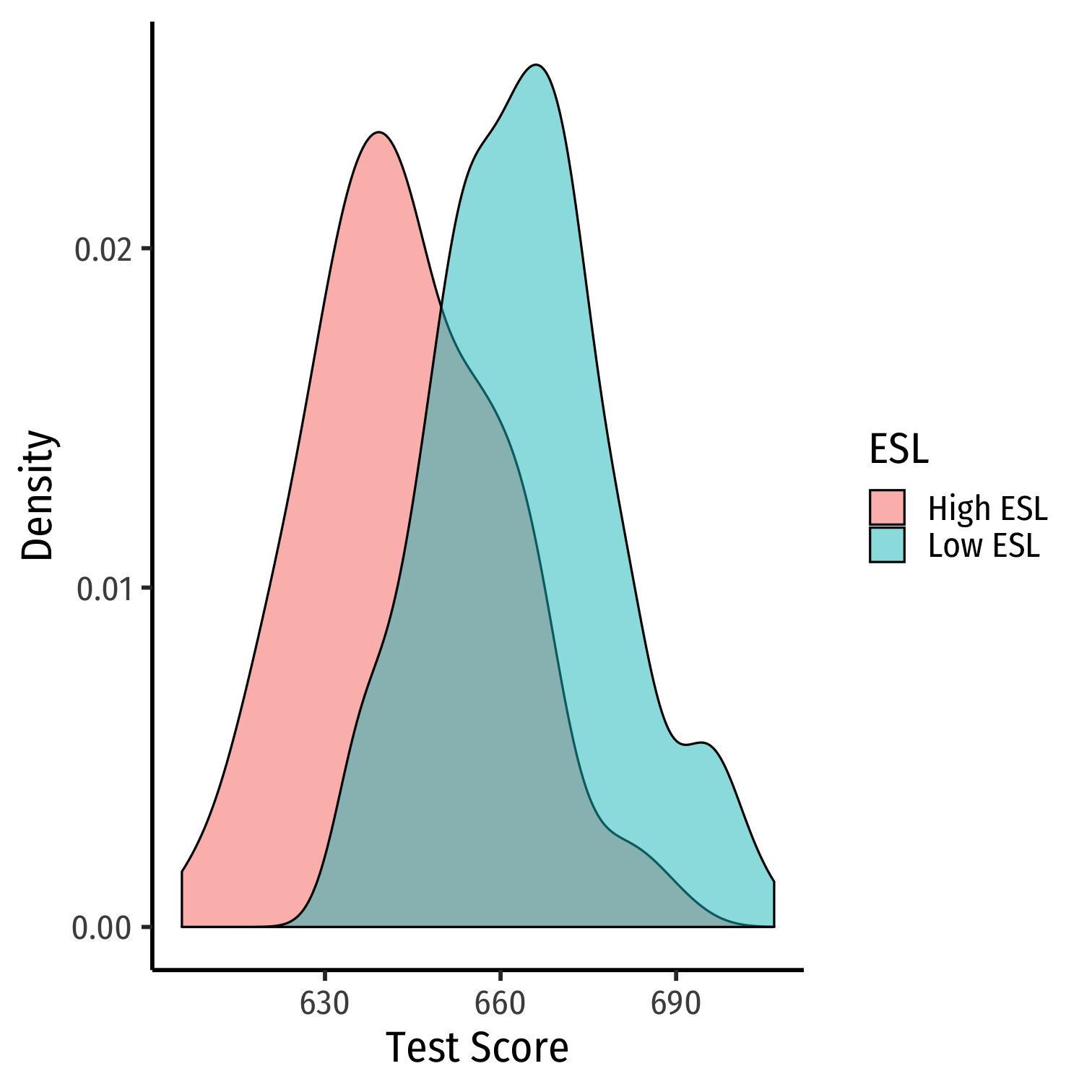
Look at Conditional Distributions III
cond_el_scatter<-ggplot(data = CASchool)+ aes(x = str, y = testscr, color = ESL)+ geom_point()+ geom_smooth(method="lm")+ labs(x = "STR", y = "Test Score")+ theme_classic(base_family = "Fira Sans Condensed", base_size=20)cond_el_scatter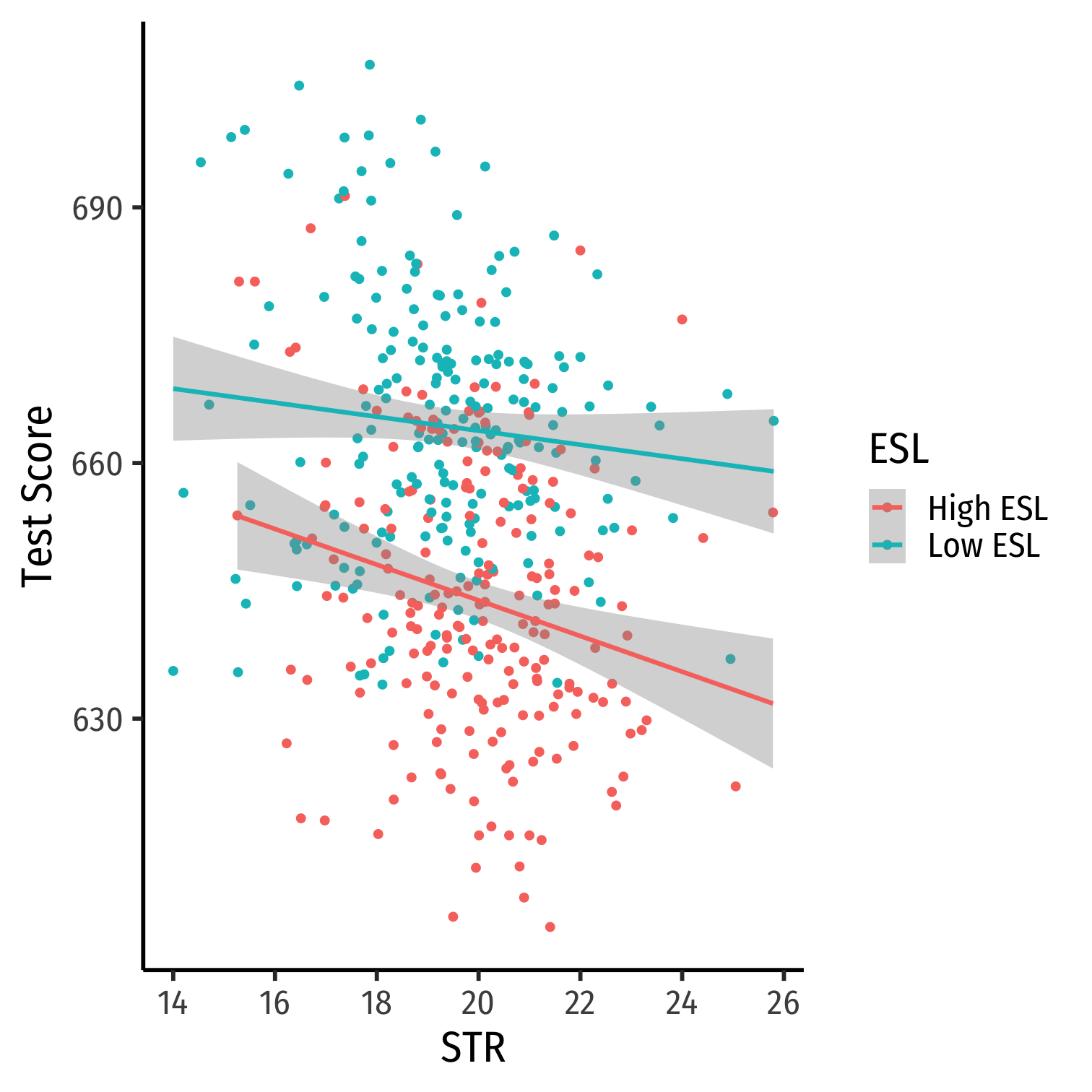
Look at Conditional Distributions III
cond_el_scatter+facet_grid(~ESL)+ guides(color = F)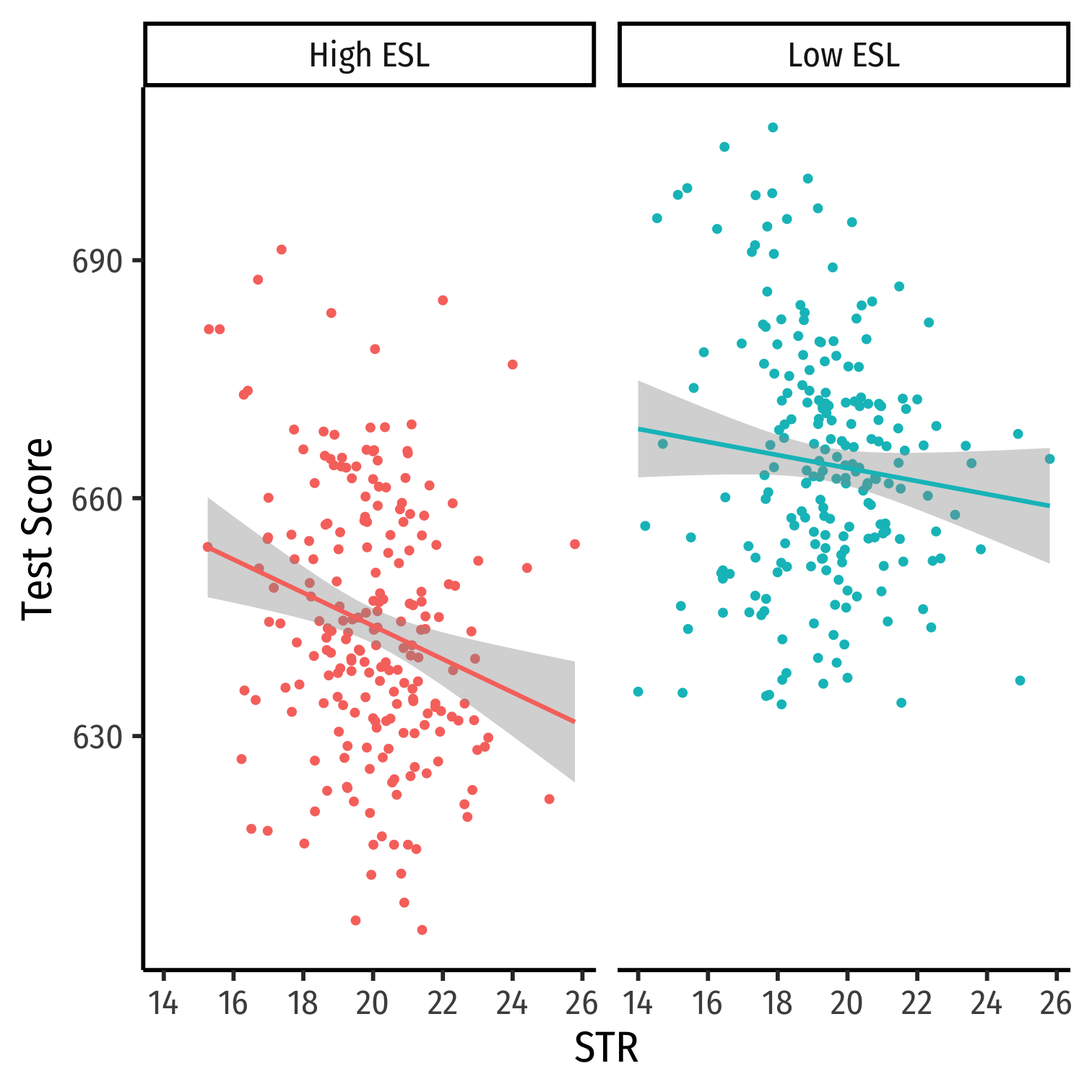
Omitted Variable Bias: Messing with Causality II
Recall our best working definition of causality: result of ideal random controlled trials (RCTs)
Randomly assign experimental units (e.g. people, cities, etc) into two (or more) groups:
- Treatment group(s): gets a (certain type or level of) treatment
- Control group(s): gets no treatment(s)
Compare results of two groups to get the causal effect of treatment (on average)

RCTs Neutralize Omitted Variable Bias I
Example: Imagine an ideal RCT for measuring the effect of STR on Test Score
School districts would be randomly assigned a student-teacher ratio
With random assignment, all factors in u (family size, parental income, years in the district, day of the week of the test, climate, etc) are distributed independently of class size

RCTs Neutralize Omitted Variable Bias II
Example: Imagine an ideal RCT for measuring the effect of STR on Test Score
Thus, cor(STR,u)=0 and E[u|STR]=0, i.e. exogeneity
Resulting ^β1 would be an unbiased estimate of β1, the true causal effect of Δ STR →Δ Test Score
But We Rarely, if Ever, Have RCTs
But our data is not an RCT, it is observational data!
"Treatment" of having a large or small class size is NOT randomly assigned!
Again, %EL: plausibly fits criteria of O.V. bias!
- %EL is a determinant of Test Score
- %EL is correlated with STR
Thus, "control" group and "treatment" group differs systematically!
- Small STR also tend to have lower %EL; large STR also tend to have higher %EL
- Selection bias: cor(STR,%EL)≠0, E[ui|STRi]≠0
 Treatment Group
Treatment Group
 Control Group
Control Group
There's Another Way to Reduce OVB
Look at effect of STR on Test Score by comparing districts with the same %EL.
- Eliminates differences in %EL between high and low STR classes
- "As if" we had a control group! Hold %EL constant
The simple fix is just to not omit %EL!
- Make it another independent variable on the righthand side of the regression
Treatment Group
Control Group
Multivariate OLS in R IV: broom

# load packageslibrary(broom)# tidy regression outputtidy(school_reg_2)term <chr> | estimate <dbl> | std.error <dbl> | statistic <dbl> | |
|---|---|---|---|---|
| (Intercept) | 686.0322487 | 7.41131248 | 92.565554 | |
| str | -1.1012959 | 0.38027832 | -2.896026 | |
| el_pct | -0.6497768 | 0.03934255 | -16.515879 |